
{kind=link}
Web crawler
From Wikipedia, the free encyclopedia
From Wikipedia, the free encyclopedia
For the search engine of the same name, see WebCrawler. For the fictional robots called Scutters, see Red Dwarf characters#The Skutters.
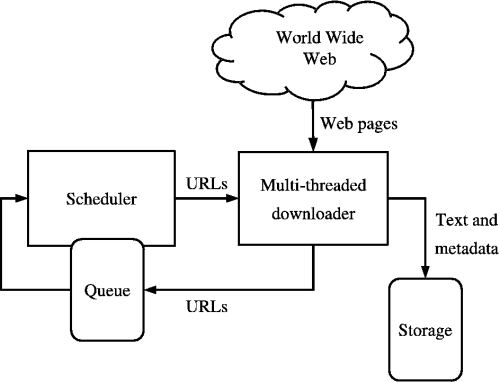
A Web crawler is a computer program that browses the World Wide Web in a methodical, automated manner or in an orderly fashion. Other terms for Web crawlers are ants, automatic indexers, bots, [1] or Web spiders, Web robots, or—especially in the FOAF community—Web scutters[2].
This process is called Web crawling or spidering. Many sites, in particular search engines, use spidering as a means of providing up-to-date data. Web crawlers are mainly used to create a copy of all the visited pages for later processing by a search engine that will index the downloaded pages to provide fast searches. Crawlers can also be used for automating maintenance tasks on a Web site, such as checking links or validating HTML code. Also, crawlers can be used to gather specific types of information from Web pages, such as harvesting e-mail addresses (usually for spam).
A Web crawler is one type of bot, or software agent. In general, it starts with a list of URLs to visit, called the seeds. As the crawler visits these URLs, it identifies all the hyperlinks in the page and adds them to the list of URLs to visit, called the crawl frontier. URLs from the frontier are recursively visited according to a set of policies.
Source: http://en.wikipedia.org/wiki/Web_crawler#Crawler_identification.
Source: http://en.wikipedia.org/wiki/Web_crawler#Crawler_identification.
Thanks for the "lingo", M. Anon!
.
No comments:
Post a Comment